
Work with Issues
Here, we can demonstrate how HAPI simplifies creating and updating issues. This section also explains how to transition issues in Jira, including updating fields during transitions. Additionally, HAPI streamlines issue searching, enabling you to run JQL queries with ease.
Create Issues
HAPI allows you to quickly and easily create issues and set parameters.
You can use the following code to create an issue:
groovyIssues.create('ABC', 'Task') { setSummary('my first HAPI 😍') }
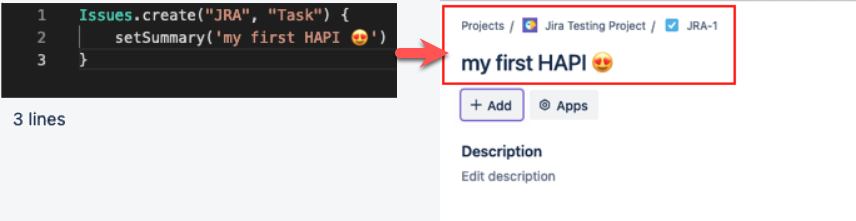
The script above sets only the four fields that are always required when creating an issue in Jira:
- Project
- Issue type
- Summary
- Reporter (automatically defaults to the current user).
The above code will fail if other mandatory fields are set through the configuration scheme. Either set those fields or test on a project with the default configuration scheme.
Populate additional fields when creating issues
When creating an issue, you have the option to populate additional fields to provide more detailed information. For a comprehensive list of available fields, refer to our Javadocs.
Here are a few examples of additional fields you might want to specify, along with the format to use when creating an issue:
groovyIssues.create('JRA', 'Task') { setSummary('my first HAPI 😍') setPriority('High') setDescription("HAPI issue description") setLabels('Test1') setFixVersions("1.1") setCustomFieldValue('Story Points', 5) }
After you enter set you can use the keyboard shortcut control + space to show available completions.
Create a subtask
To create a subtask, use createSubTask and specify the subtask issue type. You can also add additional fields such as Summary, Description, and more to provide detailed information. For example:
groovyIssues.getByKey('ABC-1').createSubTask('Sub-task') { setSummary('This is the summary') setDescription("This is the description") }
The createSubTask method can actually create all kinds of child issues, depending on the level of the current issue. In an Epic, you can use it to create child issues such as story, task, bugs, and so on.
Update Issues
In this example we're updating the summary of an issue and setting the description.
You can update an issue as follows:
groovydef issue = Issues.getByKey('ABC-1') issue.update { setSummary('an updated summary') setDescription('hello *world*') setPriority('Medium') }
The example below shows that you can update multiple fields at once:
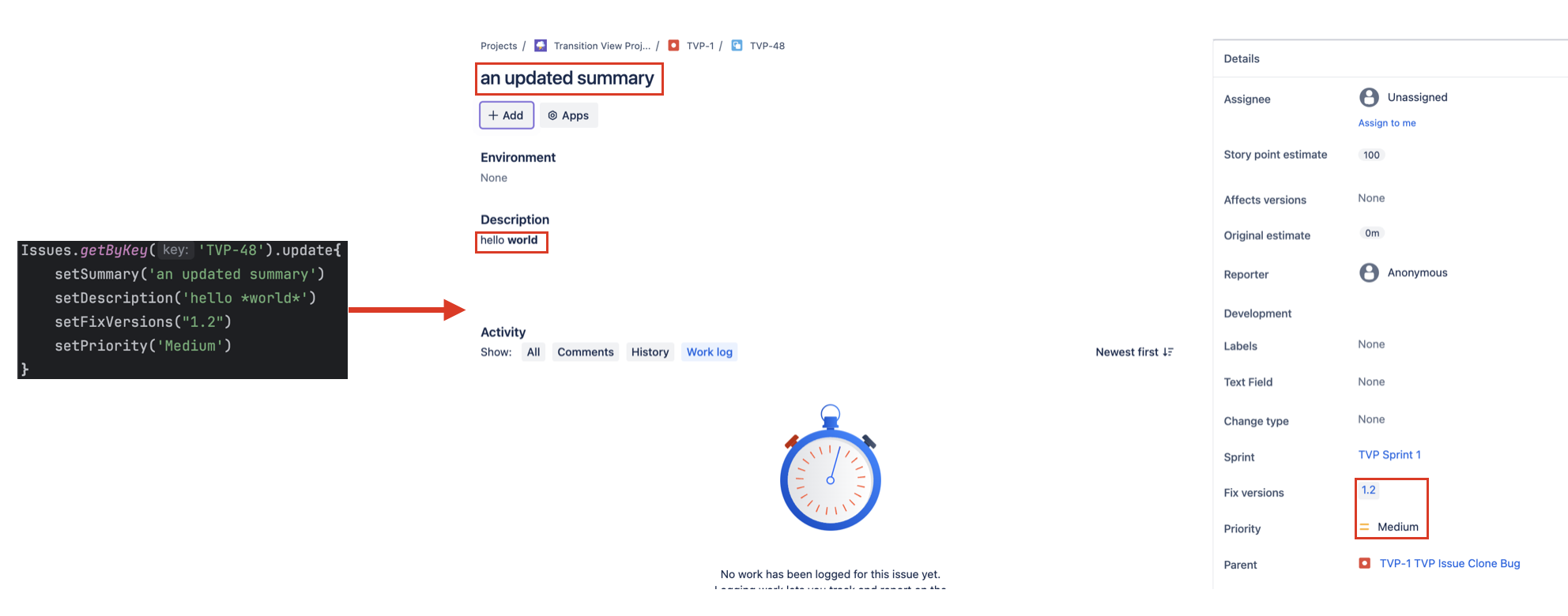
The issue variable above is a standard com.adaptavist.hapi.cloud.jira.issues.Issue. So you can update an issue like this anywhere you have a com.adaptavist.hapi.cloud.jira.issues.Issue object.
Refer to the Javadocs for a complete list of methods available for updating an issue.
Transition an issue
Link and Unlink an issue
Linking issues in Jira establishes a relationship between two issues, such as marking one issue as blocking another. This helps maintain traceability and visibility across related tasks.
Here’s an example of linking two issues:
groovyissue.link('blocks', Issues.getByKey('ABC-2'))
To unlink an issue, you can remove the existing link:
groovyissue.unlink('blocks', Issues.getByKey('ABC-2'))
This functionality makes it easier to manage dependencies and track issue relationships effectively.
Transition Issues
With HAPI, we've made it easy for you to transition issues and even update fields while you transition issues.
To transition an issue in Jira, you can use the following script in the script console:
groovydef issue = Issues.getByKey('ABC-1') issue.transition('In Progress')
Transitioning an issue moves it from one workflow status to another, reflecting its current state or progress. For instance, once the work on an issue is completed, you can transition it to the Done status.
Here’s another example of transitioning an issue using HAPI:
groovyissue.transition('Done')
Update Fields While Transitioning Issues
Watch our short demo video to understand how this works:
You can update fields, such as modifying the summary or adding comments, as part of the transition process. For example:
groovydef issue = Issues.getByKey('ABC-1') issue.transition('Done'){ setSummary('Issue to be transitioned to done') setComment('Issue is completed') setPriority('Low') }
![]()
To update fields, such as the Summary or any other field, during a transition, ensure that these fields are included in the Transition View Screen for the corresponding workflow transition. Without this configuration, the fields cannot be updated as part of the transition process.
This setup allows transitioning an issue to not only update its status but also capture additional relevant context, enhancing clarity and record-keeping.
Search for Issues
With HAPI, we've made it easy for you to search for issues.
Run JQL queries to search for issues
You can easily run JQL queries.
In this example we're running a query that returns all issues of issueType 'Bug' in the 'JRA' project.
Where the example says "do something with each issue" you can, for example, update all returned issues using the issue.update method.
groovyIssues.search("project = 'JRA' AND issuetype = 'Bug'").each { issue -> // do something with `issue` }
Issues.search returns an Iterator. This is designed for you to iterate through the results instead of retaining many issues in memory.Update all returned issues
As previously mentioned, you can update all returned issues using the issue.update method. This is particularly useful if you want to bulk update issues.
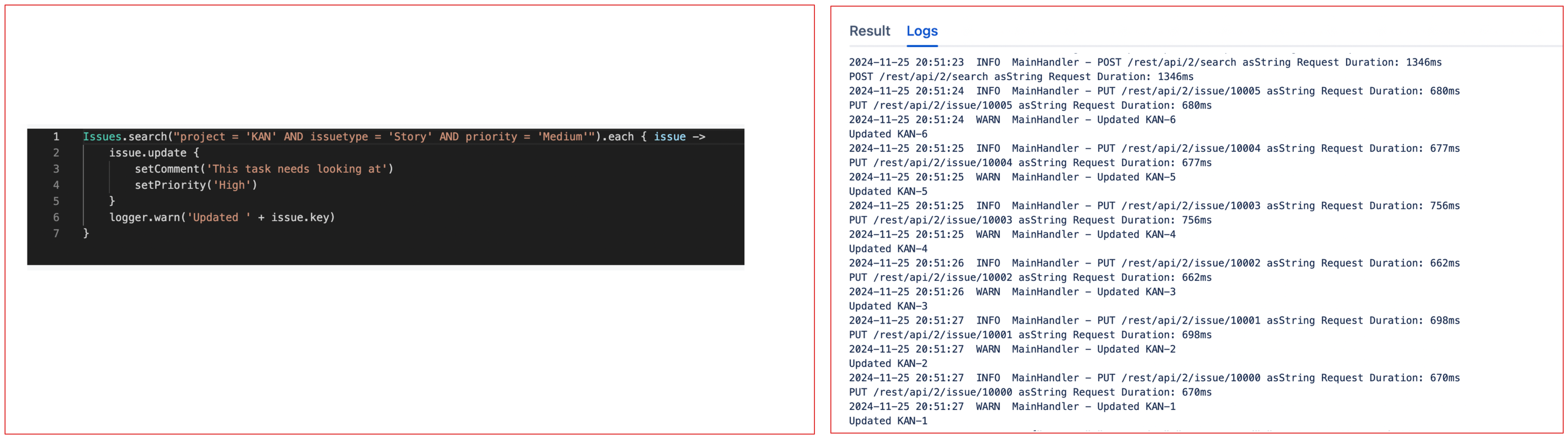
In this example we're running a query to return all medium priority stories in project 'KAN'. At the same time we're adding a comment to all returned issues, setting the priority to 'High', and printing a line of log.
groovyIssues.search("project = 'KAN' AND issuetype = 'Story' AND priority = 'Medium").each { issue -> issue.update { setComment('This task needs looking at') setPriority('High') } logger.warn('Updated ' + issue.key) }
JQL queries and memory
We recommend that you do NOT execute queries using an unlimited PagerFilter. The returned issues are temporarily stored in memory if you execute a query without paging.
With HAPI, the retrieval of issue ensures that memory usage is constant, and that you don't cause an OutOfMemoryException.
Limit list size for JQL queries
If you require a List of issues, limit the size, as shown below.
groovyIssues.search("project = 'KAN' AND issuetype = 'Story' AND priority = 'High'").take(10).toList()
In terms of memory usage, having one thousand issues in a List is acceptable, tens of thousands might be feasible, but handling millions is not advisable.
If you need a count of issues, use count. This provides better performance than executing a query and iterating through them all just to count them:
groovyIssues.count('project = JRA')
Advanced HAPI JQL usage
You may want to filter the list of issues further because you want a condition you cannot express in JQL.
In this example we're filtering issues assigned to James Smith only. This is just for demonstration purposes: it is easier to express this in JQL.
groovyIssues.search('project = KAN').findAll { issue -> issue.assignee?.name == 'James Smith' }.each { issue -> // perform operations on issue logger.info("${issue.key} assigned to ${issue.assignee?.displayName}") }
Limiting the number of issues searched
Groovy Development Kit methods such as findAll collect as many issues as they can, which isn't ideal. If you have a very large instance for tasks such as the one above or advanced data processing pipelines, you can use the java Streams API. The stream() method is available on the search result for convenience.
In this example we're filtering issues assigned to James Smith only and limiting the results to 5.
groovyimport java.util.stream.Collectors Issues.search('project = JRA') .stream() .filter { issue -> issue.assignee?.displayName == 'James Smith' } .limit(5) .collect(Collectors.toList())