
Database Connection
To set up a connection to an external database, you need to know the following information for the database:
The JDBC URL
Any required credential information (username and password)
The driver class
Your database administrator should be able to provide this information if you do not know it.
To set up an external database connection and make the database available to scripts:
Navigate to ScriptRunner > Resources > Create Resource > Database Connection.
Provide a name for the connection in Pool Name.
Enter the JDBC URL of the database to which you wish to connect.
For more information on sample JDBC URLs, see JDBC Driver Connection URL Strings.Provide the Driver Class Name.
Select Show examples to see a list of common driver classes.
Enter the username required to authenticate the database in User and the corresponding Password.
The User and Password fields are not required if the information is provided in the URL.
- Optional: Select if this database connection should be read only.
Optional: Enter a query into the SQL field to test receiving information from the database. Use Preview to test out different queries.
This SQL query is not saved and is only used to test the connection.
Optional: Set advanced connection pool properties, such as the maximum pool size. This may be useful in several cases:
By default, the database resource will take 10 connections. On Data Center this is 10 connections per node in your cluster.
If this totals too many connections, you can limit the maximum size by entering, for example:
maximumPoolSize=3.If you would like to limit a database session to ten minutes, enter
maxLifetime=600000(ten minutes in milliseconds).If you see connections are growing, it could be that a prepared statement was not closed. Enter
leakDetectionThreshold=2000to report any connection that was borrowed from the pool for more than two seconds.Look for an exception in your logs beginning:
java.lang.Exception: Apparent connection leak detected.If your database query is expected to take more than two seconds, then this is probably not a leak, and you should raise this value.
If the preview is successful, select Add.
Other Drivers
You might want to use these to create a custom field that allows users to pick from a row in a spreadsheet.
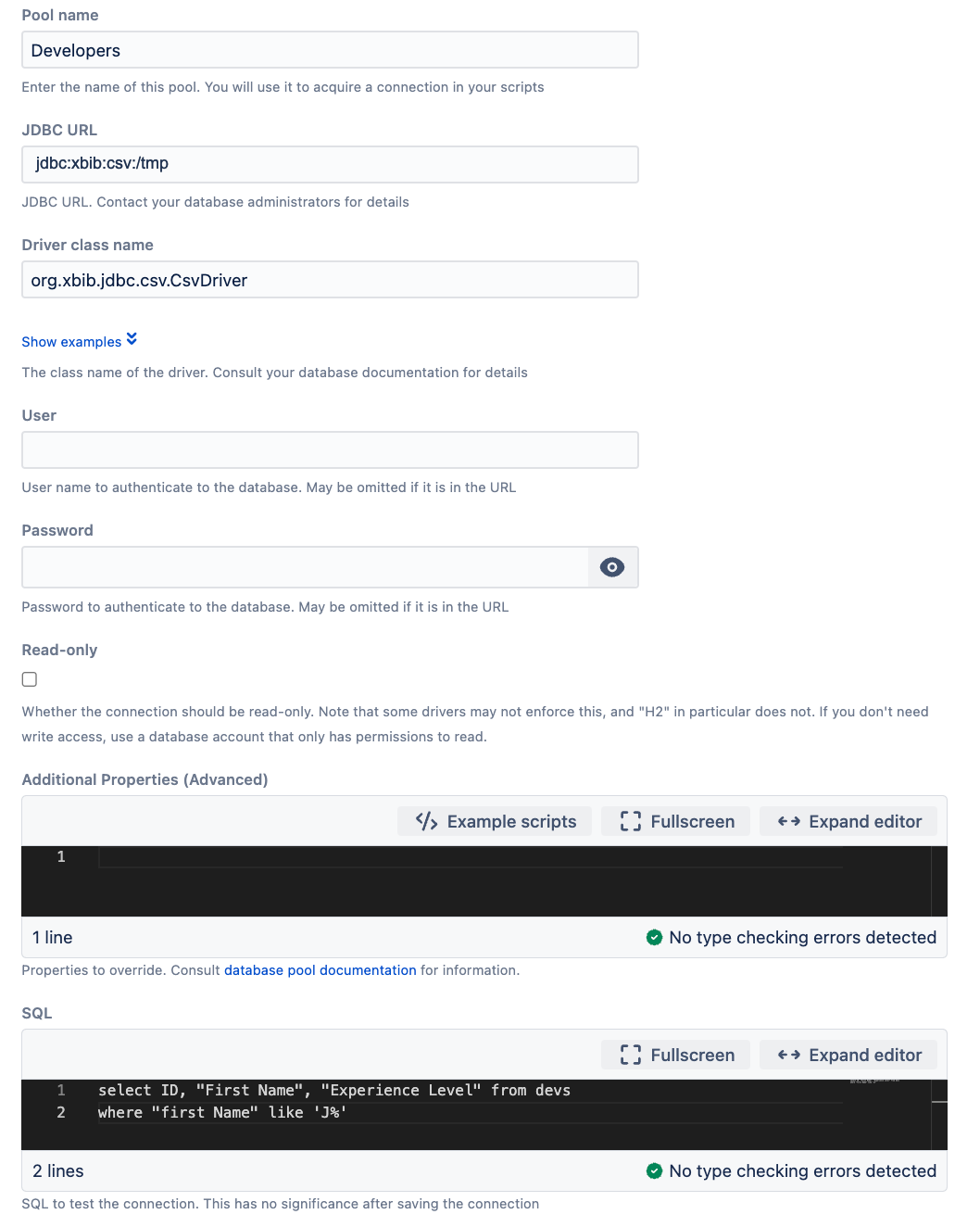
In the example shown below, we are using a CSV driver. This makes available all CSV in the directory provided in the JDBC URL. So in /tmp, we have a CSV file called devs.csv.
If you need to use another database driver (like an Excel or CSV driver), copy it into the tomcat lib directory of your installation and restart. For example, this could be /opt/<application>/lib/.
- Download this CSV driver (or a driver of your choice) and place it in the tomcat lib directory.
- Restart Jira for the changes to take place.
- Add the database connection using the following parameters:
- JDBC URL: jdbc:xbib:csv:/tmp
- Driver class name: org.xbib.jdbc.csv.CsvDriver
Alternatively use the following driver:
- Download the alternative CSV JDBC driver and place it in the tomcat lib directory.
- Restart Jira for the changes to take place
- Add the database connection using the following parameters:
- JDBC URL: jdbc:relique:csv:/tmp
- Driver class name: org.relique.jdbc.csv.CsvDriver
Both of the CSV drivers mentioned above were not designed to be used from more than one thread at a time. ScriptRunner's Database Connection resource use JDBC connection polling, with the poll size larger than 1 by default. This can potentially lead to multiple threads using the driver at the same time, leading to indeterministic behaviour and exceptions while using the CSV drivers. To prevent this from happening, you should set the connection pool size to 1.
Set the following in the Additional Properties configuration field on the Database Connection resource configuration screen:
maximumPoolSize=1
Use database connections in scripts
Having set up a local connection, you can use it in a script as follows:
groovyimport com.onresolve.scriptrunner.db.DatabaseUtil DatabaseUtil.withSql('local') { sql -> sql.rows('select * from project') }
DatabaseUtil.withSql takes two arguments:
The name of the connection as defined by you in the Pool Name parameter when adding the connection (in this example local),
A closure. The closure receives an initialized
groovy.lang.Sqlobject as an argument. See executing SQL for more information on executing queries. The benefit of using a closure is that it is returned the connection to the pool after execution.Compare with the alternative method of executing a query.
The withSql method returns whatever the closure returns. For example, you could get the number of projects using:
groovyimport com.onresolve.scriptrunner.db.DatabaseUtil def nProjects = DatabaseUtil.withSql('local') { sql -> sql.firstRow('select count(*) from project')[0] }
You could also retrieve projects as follows:
In the following example we want to retrieve a list of Project objects for Project A.
groovyimport com.onresolve.scriptrunner.db.DatabaseUtil import com.atlassian.jira.project.Project def projects = DatabaseUtil.withSql('local') { sql -> sql.rows("select pkey from project where pname = 'Project A'").collect { row -> Projects.getByKey(row.pkey as String) } } as List<Project> projects
We use the above script to query the database and collect the project keys, then use them to get the project objects.