
Script Fields
Extend the information shown for an issue using ScriptRunner Script Fields. Use Groovy to calculate or consolidate data from one or more existing fields and display them in custom fields.
You cannot manually edit the value, or update the value of a script field as the value is calculated at the time an issue is displayed or updated (in exactly the same way as a custom field plugin). It is possible to search on these values if you set up one of the four shipped searchers. If you do, the value is calculated and stored in the index at the time that the issue is indexed, for example, when it is modified or transitioned, or when you do a full reindex.
You could use a script field to:
- Pull in data from an external system (such as a connected database).
- Show a value from a linked instance.
- Show a value calculated from the values of other issue fields.
- Show a value calculated from the values of fields in other issues.
ScriptRunner Script Fields are not available on the Issue Detail view of scrum or kanban boards.
New to Script Fields? Check out our Script Field Tutorial.
Getting Started
The Script Fields page displays the different field configurations for this field type. It’s possible to have different scripts for different field configs for the same custom field, but don’t do this right now to keep things simple.
Click the "Add New Item" button (see screenshot below) to see a list of built-in script fields available.

Select the "Custom Script Field" option
You can either point to a script accessible to Jira using an absolute path, or a path relative to Jira’s working directory (preferred), or type your script in inline.
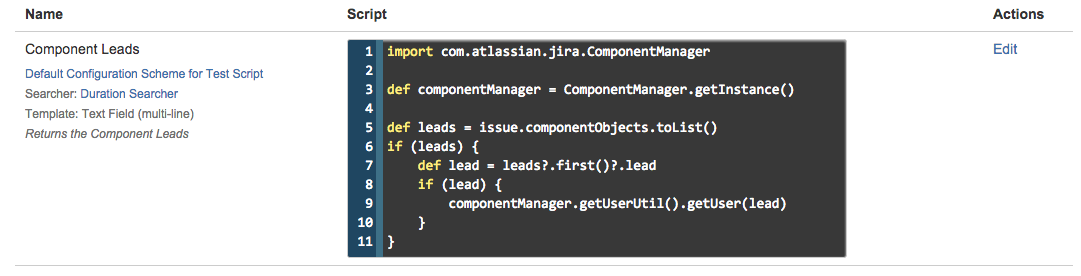
The final part of configuration is to choose which renderer to use. The renderer also determines which issue panel, eg Dates, People, or the default main panel the value will be shown in in the view issue screen. As of 3.0, script fields using either user template can be used in notification schemes, which means you can dynamically generate the recipient of an email, eg based on component lead, priority, etc.
The names are taken from one of the internal Jira files so might not seem to make total sense. Use the following table as a guideline for which one to use:
| Your script returns… | Template | Issue Panel |
|---|---|---|
A string | Free text field | main |
A string as html | HTML | main |
A date | Date Time | Dates |
A number | Number Field | main |
A user | User Picker | People |
List of users | Multi User Picker | People |
A group | Group Picker | main |
List of groups | Multi Group Picker | main |
A project | Project Picker | main |
Something else | Custom | main |
When getting started use the "free text" template without any indexer.
Obviously all of these three things need to tally:
Your return type from the script
The indexer if you are using one
The template Next, get the key of an existing issue and enter it in the "Preview … " box, and press Go. Your script will be compiled and executed using the issue, so you can see how the field will appear on that particular issue.
Depending on the complexity of the script you will need to test with multiple issues and different inputs.
Indexing Free Text Fields
If you use one of the built-in text searchers, you can query on this field.
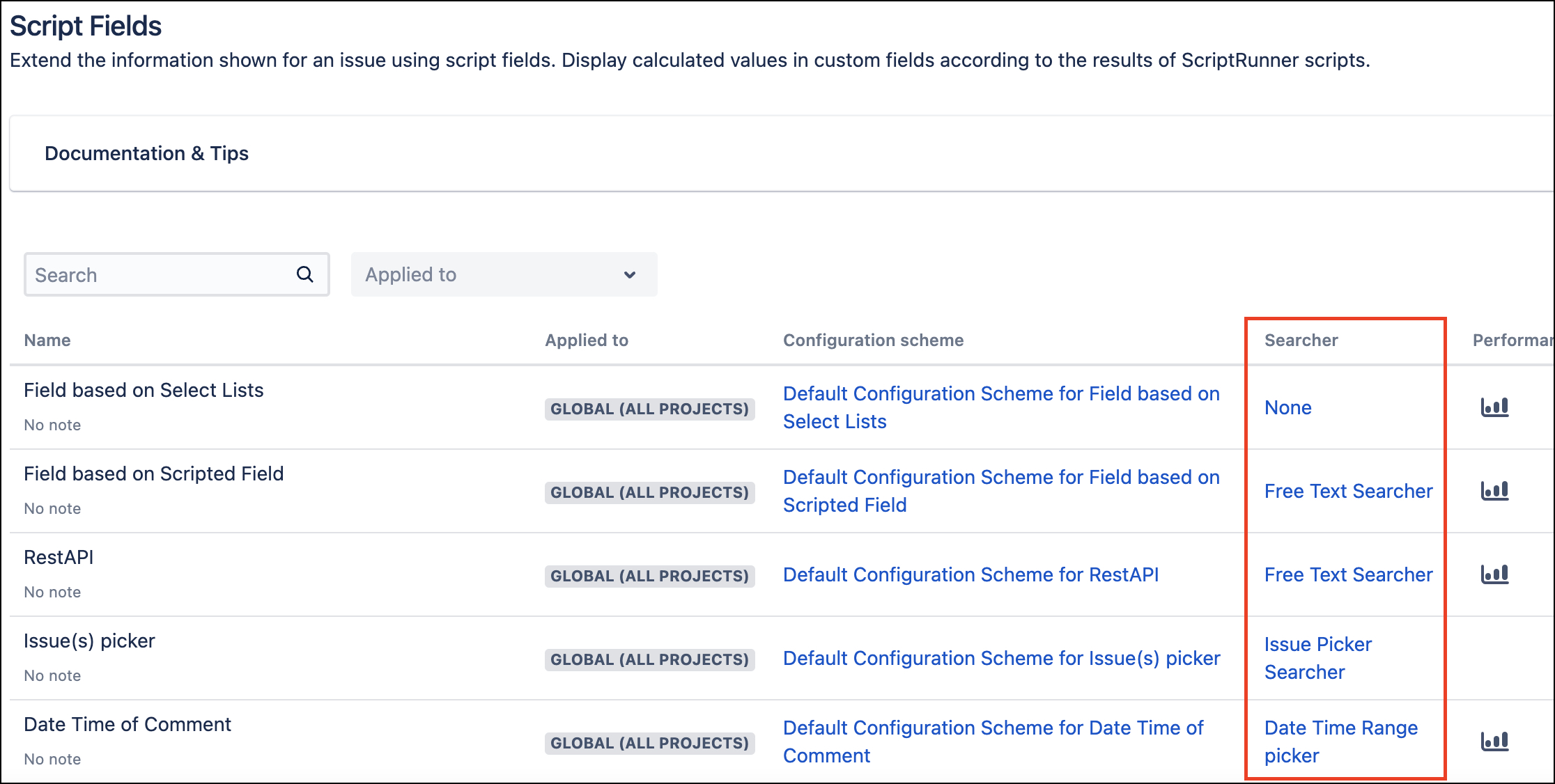
To use them in filter statistics gadgets (for example Two Dimensional Filter Statistics or Heatmap), select one of the Stattable searchers:
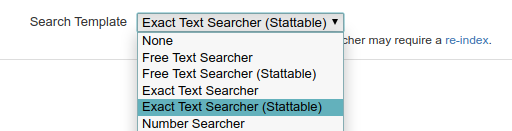
If you create a script field with a given Template from the ScriptRunner interface, some of the selectable templates will set the custom field's configured Search Template for you on creation. Make sure to choose the correct template before you create your field because once you have a searcher defined, it may require a full re-index to change it to another Search Template if the types are incompatible.
Be cautious when converting to the Stattable version of indexers. Stattable searchers can be used in gadgets (as described above). In instances with hundreds of thousands of possible unique string values, the memory demand of Jira increases and may run out if required to render gadgets for fields using these searchers. Therefore, you should only use these indexers if your script field generates a finite number of possible string values (several thousand should be fine).
Caching
It’s worth expanding a little on what I said above. You can only reliably use a calculated field to display a value that is based on the issue’s fields, or subtasks' fields, or linked issues. The reason why is because the value in the Lucene index is only updated when the issue is updated. If you compute some value based on data outside of the current issue, the value in the index may differ from the value displayed on the issue.
Jira asks the field for the value a ridonkulous amount of times - 8 times just for viewing an issue. This means your script will be executed 8 times. Therefore there is a thread local cache… for subsequent requests the computed value is just retrieved from the cache. If the issue has a different last update date the cache is invalidated. As of 2.1.4 (not released at time of writing), the following actions now also invalidate the cache - changes to the script text (for inline scripts) and changes to the last modified date of the script file, if you are using one. If, in previous versions of the plugin, refreshing the page showed a different value, it’s because different threads had different cached values - that should be fixed in 2.1.4.
If your script relies on data from external system you can invalidate the cache altogether, although you should test first, particularly if you are doing things like running complex JQL queries. To disable the cache add the following line to your code:
groovyenableCache = {-> false}
That’s an example for disabling it completely, you can use any other variables to return a Boolean. You may have to do this if you are computing data from linked issues, however the indexed value should always be correct.
What if your field relies on data outside its scope and you want to search on it? You can’t, Jira doesn’t have this capability… write your own searcher.