
Calculations
expression
expression(Subquery, expression)This is an absurdly powerful function that lets you compare attributes of fields. What you can compare are the system estimate and date fields, and any numeric, date, or datetime custom field. It’s probably easiest to explain through some examples, starting from the simple.
Find issues where more work was logged than originally estimated:
issueFunction in expression("", "timespent > originalestimate")Note that this could also be done by using plain JQL: workratio > 1. However with plain JQL, you could not find issues which are likely to exceed their estimate:
issueFunction in expression("", "timespent + remainingestimate > originalestimate")You would probably want to use resolution is empty as the subquery, to filter out issues that have been completed.
Search for issues where the work logged exceeded the original estimate by more than 5 days (normalised for timetracking, so > 40 hours work logged):
issueFunction in expression("", "timespent > originalestimate + 5*wd")Do use 5*d or 5*wd and not 5d as in dateCompare - the syntax is (unfortunately) different.
Notes on time tracking
Unfortunately, a "day" can mean different things in different contexts. When comparing dates, we normally think in terms of the difference between two dates being 24 hour days.
However if we are comparing estimate fields, a day is normally thought of as an 8-hour working day, or whatever the Jira time tracking is configured to be. Similarly, a week consists of 5 working days usually.
Previous versions of this function tried to do the conversion for you automatically. However this was confusing, so if you want to compare estimates adjusted for time-tracking, you now need to explicitly specify either working day units:
wd
Number of milliseconds in a working day (according to your specification in Admin → Time tracking
ww
Number of days in a working week multiplied by the value above.
Or, if you are comparing timetracking fields with non-time tracking fields, for example remaining effort and due date, you need to use the special fromTimeTracking function. For example, search for issues which, if their remaining estimate is valid, are going to miss their due date. You could devote extra resources to these to ensure that doesn’t happen:
issueFunction in expression("resolution is empty", "now() + fromTimeTracking(remainingestimate) > duedate")When you specify an estimate of 3 days, Jira stores that internally as 24 hours, and renders it as 3 days for estimate fields. The fromTimeTracking function converts that to 72 hours so it can be used to manipulate and compare with other dates.
Find issues where the product of two number custom fields is greater than X:
issueFunction in expression("", "StoryPoints * BusinessValue > 100")Custom field names are likely to have spaces, which can’t be parsed. If so, remove the spaces. It’s not case-sensitive but use camel-case for maximum readability. If your field names have any other punctuation you must use the format customfield_12345.
You can only use custom fields that have a configured searcher, as, for performance reasons, we only retrieve values from the Lucene index. The standard searchers are supported, searchers supplied by plugins will not work.
Find issues where the creator is not equal to the reporter
issueFunction in expression("", "creator != reporter")Find issues that were due on the same day they were created:
issueFunction in expression("", "created.clearTime() == dueDate")Or find issues with a specific due date:
issueFunction in expression("", "dueDate == date('2018-05-10')")Use date function when you need to compare date in expression. The function takes date as string and returns a timestamp. To get the desired result use clearTime with JIRA fields such as created or updated to remove time if you wish to use == operator with date function.
Find issues that have a high ratio of votes to complexity (assuming Complexity is a numeric field):
issueFunction in expression("", "votes / Complexity > 100")Conversions
Fields are passed to your expression with certain types, so you can do arithmetic and comparison:
Durations, such as time tracking or where you have used the Duration searcherProvided as a Long value of the number of millisecondsDatesA java.sql.Timestamp object. Where there is no time component such as with due date, the time portion will be set to midnight on that date. You can use the .clearTime() method to clear the time portion for == comparisons with other dates. Users A String containing the user key. This is sufficient as they are just used for equality comparisons
In addition you can add a date field to a duration and get a new date.
Using functions
You can use all of the Date and User functions, for instance now(), startOfDay() etc, anywhere you would use a date.
Some arguments will need to be quoted. For example, if you want to say one week before the start of the month you would write startOfMonth('-1w').
aggregateExpression
Often you have a requirement to show some summary data based on the issues in the filter, for instance, you select all open issues in a version, and you want to see the total estimated time for all issues. Probably this should be called a summary function not an aggregate function, however this is a bit ambiguous in jira-land.
If you need more than simply a couple of values then you should probably consider writing a report. Most people will do these calculations in Excel anyway, but an aggregate function can draw attention to some figure, eg total remaining estimate from all issues shown in the current query.
The aggregate function is added to the JQL because in doing that, it will ensure other people who run the same query also see the summary value(s). Note that these won’t appear in excel views, or anywhere other than the issue navigator. Adding an aggregate function does not change the results from the query in any way.
For example, to see the total estimate for all issues in the LOAD project run this JQL:
project = LOAD and issueFunction in aggregateExpression("Total Estimate for all Issues", "originalEstimate.sum()")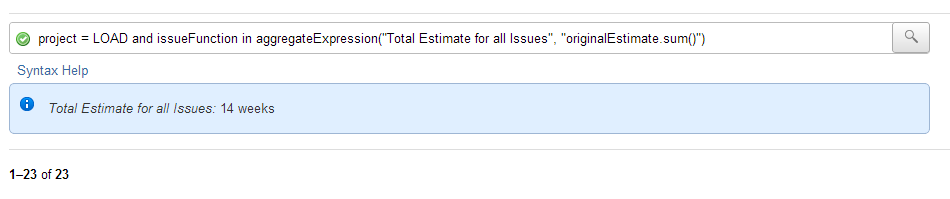
If the function has just one argument, the data label will be Aggregate data value. The expression can have multiple values, in which case use: (label1, expr1, label2, expr2, …).
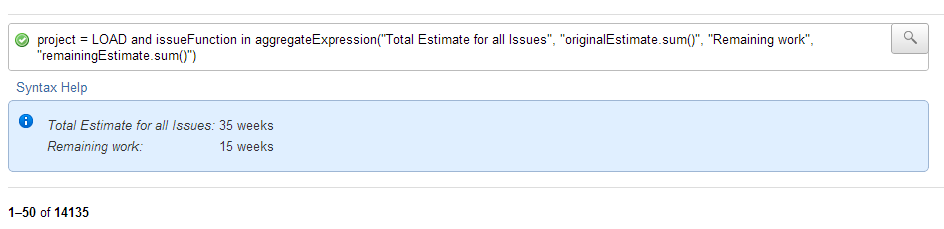
project = LOAD and issueFunction in
aggregateExpression("Total Estimate for all Issues", "originalEstimate.sum()", "Remaining work", "remainingEstimate.sum()")results in:
Some other examples for summary data:
| Note | Argument |
|---|---|
Total timespent on these issues | timespent.sum() |
Average original estimate of these issues | originalestimate.average() |
Average work ratio | workratio.average() Note: Will display as a decimal (e.g. 0.12 rather than 12%) |
Total remaining work | remainingEstimate.sum() |
Tracking error | (originalEstimate.sum() - timeSpent.sum()) / remainingEstimate.sum() |
Number of issues in this list created by user jbloggs | reporter.count('jbloggs') |
Simple breakdown of reporter but you’re probably better off using a pie chart as this is not displayed nicely at the moment | reporter.countBy{it} |
Regular Expressions
issueFieldMatch
issueFieldMatch (subquery, fieldname, regexp)Query on any field by regular expression. Performance will be roughly proportional to the number of issues selected by the subquery, so use the query that selects the smallest set of issues you can, eg just your projects. On my dev machine this function handles around 20k issues per second.
To find all issues where the description contains a ABC0000 where 0000 is any number, you could use:
issueFunction in issueFieldMatch("project = JRA", "description", "ABC\\d{4}")For a case-insensitive match, prefix the match string with (?i) - for example:
issueFunction in issueFieldMatch("project = JRA", "summary", "(?i)foo")Note - you need to double the backslashes. Note - the function searches for the reg exp anywhere within the field. To match the entirety of the field, use ^ and $, e.g. ^ABC\\d{4}$.
issueFieldExactMatch
issueFieldExactMatch (subquery, fieldname, regexp)Find issues by matching the text of a field exactly. The intention behind this function was to work around issues where the Lucene word stemming makes exact matches difficult.
Previously it was incorrectly documented that it was for an exact regex match, and may have even behaved like that. This was a bug. If you were using it like this you can achieve the same behaviour by using issueFieldMatch by specifying the start and end of line regex tokens. Eg previously you might have had:
issueFunction in issueFieldExactMatch('Some Custom Field', 'b.d')which would have matched only when the custom field was bad, bid, etc etc. To get the same behaviour you should change it to:
issueFunction in issueFieldMatch('Some Custom Field', '^b.d$')Note - you need to double the backslashes. Note - the function searches for the reg exp anywhere within the field. To match the entirety of the field, use ^ and $, e.g. ^ABC\\d{4}$.
For a case-insensitive match, prefix the match string with (?i) - for example:
issueFunction in issueFieldMatch("project = JRA", "summary", "(?i)foo")projectMatch
projectMatch(reg exp)componentMatch
componentMatch(reg exp)versionMatch
versionMatch(reg exp)These functions provide lists of projects, components, versions respectively that match the provided regular expression.
Example: all issues that have a component beginning with Web:
component in componentMatch("^Web.*")All issues in the JRA project that have a fix version beginning with RC:
fixVersion in versionMatch("^RC.*")